Blog
Abläufe und Komponenten für den Betrieb von Machine-Learning-Diensten
Von Kevin Richter am 19. Oktober 2021
Machine-Learning wird in der Industrie und Forschung bereits für verschiedenste Anwendungsfälle eingesetzt. In unserem Blog haben wir beispielsweise schon Anwendungen zur Objekterkennung, Stimmungsanalyse oder Produktempfehlung aufgezeigt. Der Lebenszyklus eines Machine Learning-Projekts umfasst typischerweise folgende Phasen:
Problem- und Zieldefinition: Zu Beginn eines Projekts werden sowohl das Problem, welches das Modell lösen soll, als auch das Ziel, das mit dem Modell erreicht werden soll analysiert und definiert.
Datensammlung: Verfügbare Daten aus verschiedenen Quellen werden gesammelt und auf ihre Verwendbarkeit und Qualität hin überprüft.
Datenvorverarbeitung: Die gesammelten Daten werden dann in eine, für das Modell verwendbare Form gebracht. In dieser Phase werden beispielsweise Datensätze aussortiert, Daten normalisiert oder neue Merkmale aus bestehenden Daten berechnet. Der erstellte Datensatz wird in dieser Phase auch in Trainings-, Validations- und Testdatensatz aufgeteilt.
Modell-Training: Auf Basis der Trainingsdaten werden dann ein oder mehrere Modelle erstellt und trainiert. Der Validationsdatensatz wird im Trainingsprozess zur Evaluation des trainierten Modells verwendet, während die Modell-Parameter angepasst werden.
Modell-Evaluation: Im Anschluss an das Training werden die Modelle auf dem Testdatensatz, dessen Daten im Training nicht verwendet wurden, evaluiert und anhand definierter Metriken miteinander verglichen.
Modell-Auslieferung (Deployment): Das Modell, welches in der Evaluation am geeignetsten scheint, wird daraufhin auf die Zielplattform transportiert. Während des Deployments werden auch Tests an der Anwendung durchgeführt.
Modell-Serving: Das Modell muss auf einer geeigneten Infrastruktur bereitgestellt werden, um bei Bedarf vom Nutzer abgerufen werden zu können und Vorhersagen zu treffen. Hierfür muss eine geeignete Schnittstelle angeboten werden.
Modell-Überwachung (Monitoring): Während das Modell im Produktivbetrieb läuft und auf unbekannten Daten, die nicht vom Modellentwickler selektiert wurden, arbeitet, werden zuvor definierte Daten protokolliert. Diese Daten können kontinuierlich überwacht und beispielsweise auf Anomalien oder sich langsam verschlechternde Werte hin analysiert werden.
Modell-Wartung: Auf Basis des Monitorings kann Handlungsbedarf entstehen. Möglich ist beispielsweise, dass die Vorhersage-Qualität nachlässt und das Modell neu trainiert werden muss. Dieses erneute Training fällt in die Phase der Modell- Wartung.
Phasen können hierbei zyklisch, auf Basis neuer Erkenntnisse bereits abgeschlossener Abschnitte wiederholt durchlaufen werden. So kann beispielsweise nach dem Training erster Modelle noch eine Anpassung in der Datenvorverarbeitung vorgenommen werden, da diese akkuratere Vorhersage-Ergebnisse verspricht.
Die Phasen bis hin zur Modell-Evaluation sind in diversen Kursen, Lehrbüchern und Tutorials breit abgedeckt. Was jedoch häufig übersehen wird ist, dass auch die besten, mühsam entwickelten Modelle nur einen geringen Nutzen für Unternehmen generieren, wenn sie nicht in eine produktiv-verwendbare Form überführt werden. In Anbetracht der Phasen und daraus resultierenden benötigten Komponenten, kann ein abstraktes Machine-Learning-System, beispielsweise wie in Abbildung 1 aussehen. Man beachte hierbei, dass das System in einzelnen Komponenten, je nach Anforderungen, Zielplattform und Architektur variieren kann. Der Quellcode rund um die Modellarchitektur, das Training und die Bereitstellung wird in einem Quellcode-Repository wie Git versioniert. Dieser Quellcode wird dann über eine Deployment-Pipeline, also einen Sequenz von Funktionen zur Auslieferung der Software, auf die gewählten Infrastrukturkomponenten, wie beispielsweise einem Server, zur Durchführung des Trainings und Bereitstellung der Vorhersagen ausgeliefert.
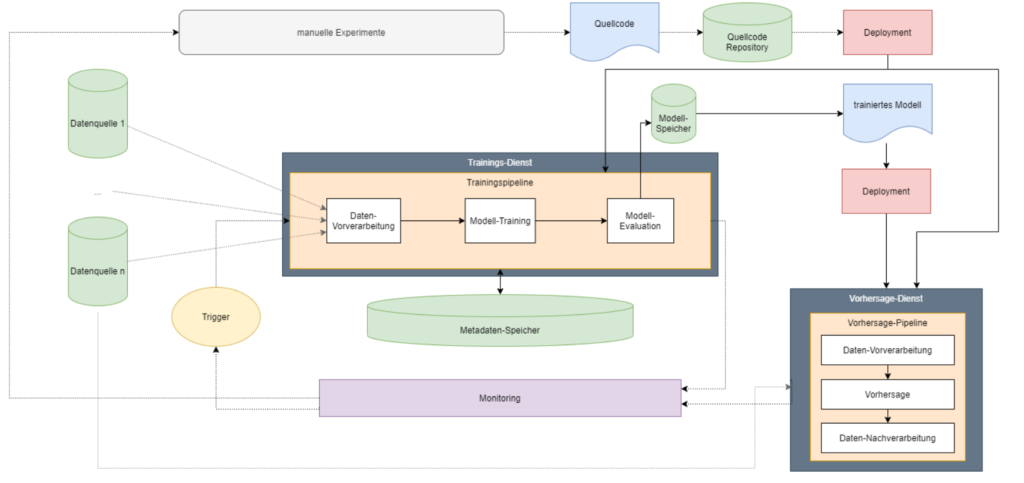
Abbildung 1: Abstrakte Darstellung eines Machine-Learning-Systems (in Anlehnung an Abbildung 3 aus MLOps: Continuous Delivery und Pipelines zur Automatisierung im maschinellen Lernen)
Wird ein Training ausgelöst, sammelt dies Daten aus verschiedenen Quellen und arbeitet dann die benötigten Trainingsschritte ab. Oft werden mehrere Modelle trainiert, die in einem Modellspeicher persistiert und ggf. versioniert werden. Während des Trainingsprozesses anfallende Metadaten werden in einem Metadaten-Speicher abgelegt. Das Speichern von Metadaten und Modellen trägt zur Nachvollziehbarkeit und Reproduzierbarkeit der Ergebnisse bei. Beispiele für Modell- und Metadatenspeicher sind MLflow oder ModelDB. Wurde ein trainiertes Modell durch Evaluationsmechanismen als bestes Modell für den gegebenen Anwendungsfall gekürt, kann dieses über eine weitere Deployment-Pipeline zur Verwendung für die Vorhersage ausgeliefert werden. Sowohl das Training, als auch die Vorhersage sollten durch ein ausführliches Monitoring überwacht werden. So kann beispielsweise bei der Vorhersage ein Drift der Eingangsdaten festgestellt werden, der eine Verschlechterung der Vorhersagen nach sich ziehen kann. Auf Basis dieses Ereignisses kann dann direkt ein erneutes Modell-Training gestartet werden, wodurch wiederum ein neues, besseres Modell erstellt und im Vorhersage-Dienst ausgetauscht wird. Es kann allerdings auch ein Data Scientist alarmiert werden, der das Ereignis und die Daten analysiert und gegebenenfalls auf Basis der Erkenntnisse eine Anpassung der Modell-Architektur vornimmt, woraus wiederum ein neues Modell erzeugt wird.
Im Folgenden werden die Phasen beleuchtet, die nach der initialen Modellentwicklung für eine dauerhafte Wertschöpfung nötig sind.
Deployment und Serving
Die eingesetzten Technologien beim Deployment von Machine-Learning-Modellen – also die Auslieferung von bereits trainierten Modellen – hängen von der Ziel-Infrastruktur ab. Bei jedem Deployment ist jedoch eine reproduzierbare Pipeline wichtig, die auch Tests enthält. Wie bei klassischer Software auch sind bei ML-Software ebenso Modul-, Integrations- und Ende-zu-Ende-Tests einzusetzen, um die gesamten Pipeline-Durchläufe, deren Integration in andere Dienste und deren Einzelkomponenten (z.B. Feature-Engineering-Funktionen) auf eine korrekte Funktion hin zu überprüfen. Jedoch ist noch eine Ergänzung um weitere Tests von Nöten, so müssen beispielsweise Daten gegen ein Schema oder das Modell auf seine Performance und Fairness hin validiert werden. Neben dem Tests zum Deployment-Zeitpunkt muss auch im Betrieb fortlaufend getestet und die weiterhin korrekte Funktionalität verifiziert werden.
Der Austausch von Modellen kann dann unter anderem entweder auf einen Schlag (Single-Deployment), parallel zum alten Modell zur Analyse, mit späterem manuellem Umschalten (Silent Deployment) oder parallel zum alten Modell, mit Verwendung durch einen Bruchteil der Benutzer (Canary Deployment) stattfinden.
Im Cloud-Umfeld können Machine-Learning-Modelle zur Vorhersage dann in unterschiedlichen Diensten bereitgestellt werden. Ist eine hohe Flexibilität bei der Umsetzung nötig, so können Dienste wie Amazon EC2 oder Amazon ECS in Amazon Web Services eingesetzt werden. Soll eine möglichst einfache und schnelle Skalierung bei geringem Konfigurations und Entwicklungsaufwand umgesetzt werden, können Dienste wie AWS Lambda oder die vollumfängliche Plattform Amazon SageMaker eingesetzt werden. Lambda unterliegt jedoch diversen Einschränkungen wie Ressourcenbegrenzungen und Cold-Start-Zeiten, derer man sich bei der Umsetzung bewusst sein sollte. Die letztliche Architektur hängt dann stark von den Anforderungen ab und ist dementsprechend von Fall zu Fall unterschiedlich.
Monitoring und Wartung
Um von Modellen fortlaufend qualitativ hochwertige Prognoseergebnisse zu erhalten, müssen kontinuierlich Daten zur Verbesserung der Prognosen gesammelt, sowie die Modelle fortlaufend überwacht und auf Verschlechterungen oder Auffälligkeiten reagiert werden. Im Rahmen eines Modell-Betriebs können unter anderem folgende Überwachungen durchgeführt werden:
Performance-Überwachung: Zur Überwachung der Modell-Performance eignen sich Metriken, die zur Modelloptimierung verwendet wurden (z.B. Accuracy, Precision oder Recall), aber auch anwendungsspezifische Metriken wie die Klickrate bei Recommender-Systemen. Diese Metriken können kontinuierlich überwacht und bei Unterschreiten eines Schwellwerts ein Ereignis ausgelöst werden.
Daten-Überwachung: Modelle werden auf historischen Daten trainiert und getestet, die meist durch einen Menschen selektiert und vorverarbeitet wurden. Bei der Bereitstellung werden die Modelle dann mit ungefilterten Daten der Nutzern konfrontiert. Hierbei können Probleme auftreten, die überwacht werden müssen. Verteilungen der Eingangs- und Ausgangsdaten sollten daher auf Drifts oder Anomalien hin überprüft werden.
Infrastruktur-Überwachung: Auch die Ausführung auf den entsprechenden Infrastrukturkomponenten sollte überwacht werden. So sind zum Beispiel die Ressourcenauslastung (CPU, GPU, Speicher) und die Ausführungsdauer von Training und Vorhersage wichtige Indikatoren, um Handlungsbedarf hinsichtlich der Skalierung oder eine plötzliche Verschlechterung nach dem Deployment einer neuen Version festzustellen.
Log-Überwachung: Während der Ausführung der Vorhersage- und Trainings-Dienste fallen diverse Ereignisse an, die protokolliert werden sollten. Neben Fehlern sind unter anderem auch außergewöhnliche Werte, Eingangsdaten, Vorhersagen und ggf. Zwischenergebnisse wichtige Daten, die betrachtet werden sollten.
Die Konsequenz aus Ereignissen genannter Überwachungen hängt vom jeweiligen Ereignis ab. Lässt beispielsweise die Performance des Modells nach, kann automatisch ein Training und Austausch des Modells ausgelöst werden. Finden sich Anomalien in den Eingangsdaten oder Vorhersagen, oder nehmen Prozesse wie Vorhersage und Training auf einmal signifikant mehr Zeit in Anspruch, so kann auch eine E-Mail an den zuständigen Data Scientist oder Data Engineer gesandt werden, der das Problem dann inspiziert und entsprechend handelt.
Fazit
Der Einsatz genannter Komponenten und Abläufe führt dazu, dass Machine-Learning-Modelle dauerhaft mit hoch-qualitativen Ergebnissen im Produktivbetrieb eingesetzt werden können. Viele Designentscheidungen und Technologien im aufgezeigten Prozess sind abhängig von den Anforderungen an die Machine-Learning Software. In diesem Blogartikel haben wir nur einen kleinen Einblick in die Operationalisierung, den Betrieb und die Komponenten von Machine-Learning-Diensten gegeben.
Wollen Sie in Zukunft benachrichtigt werden, wenn es wieder einen neuen Blogartikel gibt?
Folgen Sie uns auf LinkedIn und bleiben Sie auf dem Laufenden.
Bringen Sie Ihr Unternehmen auf die nächste Stufe!
Wir entwickeln KI-Lösungen für den innovativen Mittelstand.