Blog
Wofür wird (Deep) Reinforcement Learning angewendet?
Von Gerd Frasch am 16. Januar 2023
Die Verwendung von Neuronalen Netzen hat eine Renaissance im Bereich Reinforcement Learning (RL) eingeleitet. 2016 wurde beispielsweise der weltbeste Go-Spieler (chinesisches Brettspiel) von einem Computer mittels Reinforcement Learning überraschend geschlagen. Auch das Sprachmodell der eindrucksvollen Plattform ChatGPT basiert zu großen Teilen auf Reinforcement Learning (2).
Um das Potential von RL auszuschöpfen sind insbesondere drei Kompetenzen nötig:
- Das Erkennen und Definieren von Reinforcement Problemen
- Das Erstellen von Simulationsumgebungen auf Basis von (historischen) Daten
- Das Entwickeln von KI-Modellen mit den passenden Reinforcement Learning Algorithmen
Dieser Artikel soll einen Einblick zum ersten Punkt geben, damit Sie Reinforcement Learning Probleme in Ihrer Umgebung erkennen und möglichst genau definieren können.
Definition von Reinforcement Learning Problemen
Alle Ansätze und Algorithmen von Reinforcement Learning dienen zur Lösung von Problemen mit folgender Struktur gemäß den Markov’schen Entscheidungsproblemen:
- Es gibt einen Agenten, der bestimmte Aktionen ausführt
- Es gibt eine Umwelt, die sich in einem bestimmten Zustand befindet
- Die Aktionen des Agenten können den Zustand der Umwelt ändern
- Der Agent bekommt als Reaktion immer die Information über den neuen Zustand der Umwelt
- Außerdem bekommt der Agent eine Belohnung (oder Bestrafung) für seine letzte Aktion
- Das Ziel des Agenten ist die Maximierung der langfristig kumulierten Belohnung
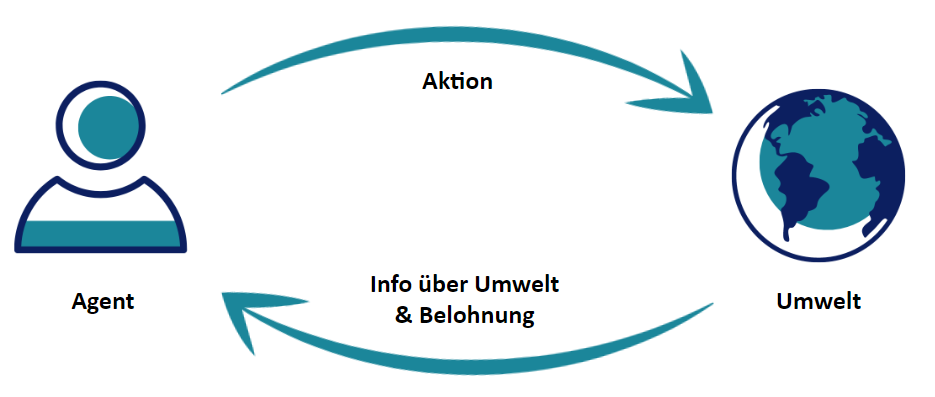
* vgl. Sutton und Barto (2018)
Diese Struktur impliziert ein Problem, welches taktisches bzw. strategisches Handeln eines autonomen Agenten voraussetzt. Genau hier liegt die Stärke vor Reinforcement Learning.
Der Agent lernt während des Trainings mittels Trial&Error immer besser abzuschätzen, wie sich bestimmte Aktionen bei gegebenen Zuständen auf die Umwelt und auf die langfristige Belohnung auswirken. Dieser Ansatz (mit Trial&Error) dazu, dass für das Training eine Simulation auf Basis einer (hohen) Menge an historischen Daten notwendig ist.
Der Agent in Form eines trainierten Modells kann dann bei hinreichender Validierung durch Data Science Experten in der realen Umgebung eingesetzt werden. Zumindest am Anfang ist ein Monitoring des Agenten in Form von Dashboards und Alerts notwendig.
Beispielhafte Problemdefinition “Smart Grid”:
Das Beispiel eines kleinen Smart Grids zur Energiesteuerung veranschaulicht die Problemdefinition sehr gut:
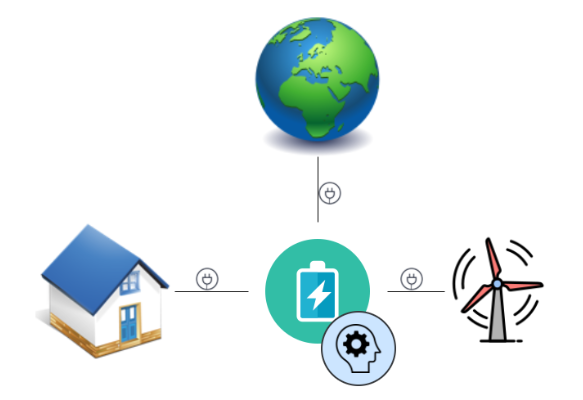
**angelehnt an Kuznetsova et al. (2013)
- Der Zustand der Umwelt wird dargestellt über den aktuellen Stromverbrauch, die aktuelle Stromproduktion des Windrades, dem Akkustand des Energiespeichers und dem aktuellen Strompreis aus dem Netz. Sinnvollerweise enthält der Zustand auch die Daten zur kurzfristigen Wetterprognose, zur Jahreszeit/Tageszeit und zu weiteren Einflussfaktoren
- Der Agent steuert den Energiespeicher mit den Aktionen Beladen, Entladen und Durchlassen
- In jedem Fall hat der Agent Einfluß auf das Smart Grid und bekommt kontinuierliche Daten zum oben beschriebenen Zustand der Umwelt
- Die Aktionen des Agenten können den Zustand der Umwelt ändern
- Der Agent bekommt als Reaktion immer die Information über den neuen Zustand der Umwelt
- Die Belohnung des Agenten besteht z.B. aus den stündlichen Stromkosten durch Einkauf aus dem Netz. Zusätzliche Bestrafungen für ein Überlasten des Energiespeichers oder ähnliches können zusätzlich Sinn machen.
- Das Ziel des Agenten ist in diesem Beispiel die Minimierung der kumulierten langfristigen Stromkosten.
Hinweis: Bei größeren Smart Grids mit Auswirkungen auf das gesamte Stromnetz (Makropersektive) würde die Umwelt sicherlich anders modelliert werden. Insbesondere würde die Stabilität des Netzes positiv bzw. Stromausfälle stark negativen Einfluß auf die Belohnung bzw. das Ziel des Agenten haben.
Zur Lösung des Problems wurde eine Simulation mit Daten über 40 Jahre erstellt und ein RL-Agent mittels einem gängigen Reinforcement Learning Algorithmus namens “Q-Learning” trainiert. Das entwickelte Modell konnte die Performance des Smart Grids steigern.**
Für Fragen bzw. einen Austausch zu den beiden technischen Punkten “Simulationsumgebungen auf Basis von (historischen) Daten” und “Entwickeln von KI-Modellen mit den passenden Reinforcement Learning Algorithmen” kontaktieren Sie uns gerne per Webformular oder rufen Sie einfach an.
* Sutton, R.S. und Barto, A.G. (2018), Reinforcement Learning: An Introduction, Auflage 2, Cambridge und London 2018 s
** Kuznetsova, E., Li, Y. F., Ruiz, C., Zio, E., Ault, G., und Bell, K. (2013), Reinforcement learning for microgrid energy management, in: Energy, 59, 2013, S. 133-146
Sie möchten mehr über die individuelle Entwicklung von KI-Projekten erfahren und interessieren sich dafür wie auch Ihr Unternehmen von Künstlicher Intelligenz profitieren kann?
Kontaktieren Sie uns gerne für eine unverbindliche Beratung.