Blog

Erfolgreiche Datenverarbeitung für Künstliche Intelligenz
Von Oliver Schick am 15. März 2023
In den letzten Jahren hat Künstliche Intelligenz (KI) zunehmend Einzug in unser tägliches Leben gehalten – von personalisierten Empfehlungen in sozialen Medien bis hin zu ChatGPT. Der Erfolg eines KI-Projekts hängt jedoch stark von der Qualität und Quantität der Daten ab, auf denen es trainiert wird. Einfach ausgedrückt: Garbage in, garbage out (Müll rein, Müll raus). Die Qualität der Daten, die zum Trainieren eines KI-Modells verwendet werden, kann sich erheblich auf dessen Leistung auswirken, während die Menge der Daten seine Verallgemeinerbarkeit und Genauigkeit beeinträchtigen kann. In diesem Blogbeitrag werden wir die entscheidende Rolle von Datenqualität und -quantität in einem KI-Projekt untersuchen und erläutern, warum sie für die Entwicklung erfolgreicher, zuverlässiger und vertrauenswürdiger KI-Systeme unerlässlich sind.
Die entscheidende Rolle der Datenqualität bei KI-Projekten
Die Datenqualität spielt eine entscheidende Rolle für den Erfolg eines jeden KI-Projekts. KI-Modelle sind auf Daten angewiesen, um zu lernen und Entscheidungen zu treffen. Wenn die Daten von schlechter Qualität sind, werden die Leistung und die Genauigkeit des Modells stark beeinträchtigt. Schlechte Datenqualität kann durch eine Vielzahl von Faktoren verursacht werden, z. B. durch unvollständige, inkonsistente oder falsche Daten, Datenverzerrungen und Datenfehler.
Unvollständige Daten können auftreten, wenn im Datensatz Werte fehlen oder wenn bestimmte Merkmale nicht erfasst werden. Wenn beispielsweise ein Datensatz zur Vorhersage von Hauspreisen keine Informationen über die Anzahl der Badezimmer in einem Haus enthält, ist das Modell möglicherweise nicht in der Lage, den Preis genau vorherzusagen. Inkonsistente Daten können auftreten, wenn die Daten in unterschiedlichen Formaten eingegeben werden oder mehrdeutig sind, so dass sie für das Modell schwer zu interpretieren sind. So kann beispielsweise der Name ein und derselben Person unterschiedlich geschrieben sein oder ein Datum kann in verschiedenen Formaten wie dem europäischen (TT/MM/JJJJ) oder amerikanischen (MM/TT/JJJJ) Format eingegeben werden, was das Modell verwirren kann.
Datenverzerrungen sind ein weiterer wichtiger Faktor, der die Qualität der zum Trainieren eines KI-Modells verwendeten Daten beeinträchtigen kann. Verzerrungen können entstehen, wenn die Daten nicht repräsentativ für die reale Welt sind, was zu verzerrten Vorhersagen führt. Wenn beispielsweise ein Einstellungsmodell auf Daten trainiert wird, die überwiegend männliche Bewerber enthalten, kann es passieren, dass das Modell männliche Bewerber gegenüber weiblichen Bewerbern bevorzugt, was zu ungerechten Ergebnissen führt.
Auch Datenfehler wie Ausreißer oder Datendopplungen können die Qualität der Daten beeinträchtigen. Ausreißer sind Datenpunkte, die erheblich von den erwarteten Werten abweichen und die Ergebnisse des Modells verfälschen können. Die Duplizierung von Daten kann zu einer Überrepräsentation bestimmter Datenpunkte führen, was wiederum zu verzerrten Ergebnissen führt.
Um eine hohe Datenqualität zu gewährleisten, müssen die Daten vor dem Training eines KI-Modells gründlich bereinigt und vorverarbeitet werden. Dazu gehört das Erkennen und Entfernen unvollständiger, inkonsistenter oder verzerrter Daten und das Korrigieren von Fehlern. Ein gut kuratierter Datensatz kann helfen, ein KI-Modell zu erstellen, das genau, zuverlässig und vertrauenswürdig ist.
Die Qualität der Daten, die zum Trainieren eines KI-Modells verwendet werden, ist entscheidend für dessen Leistung und Genauigkeit. Eine schlechte Datenqualität kann zu verzerrten, ungenauen und unzuverlässigen Vorhersagen führen, während qualitativ hochwertige Daten zu vertrauenswürdigen und robusten KI-Modellen führen können.
Die Bedeutung der Datenmenge bei KI-Projekten
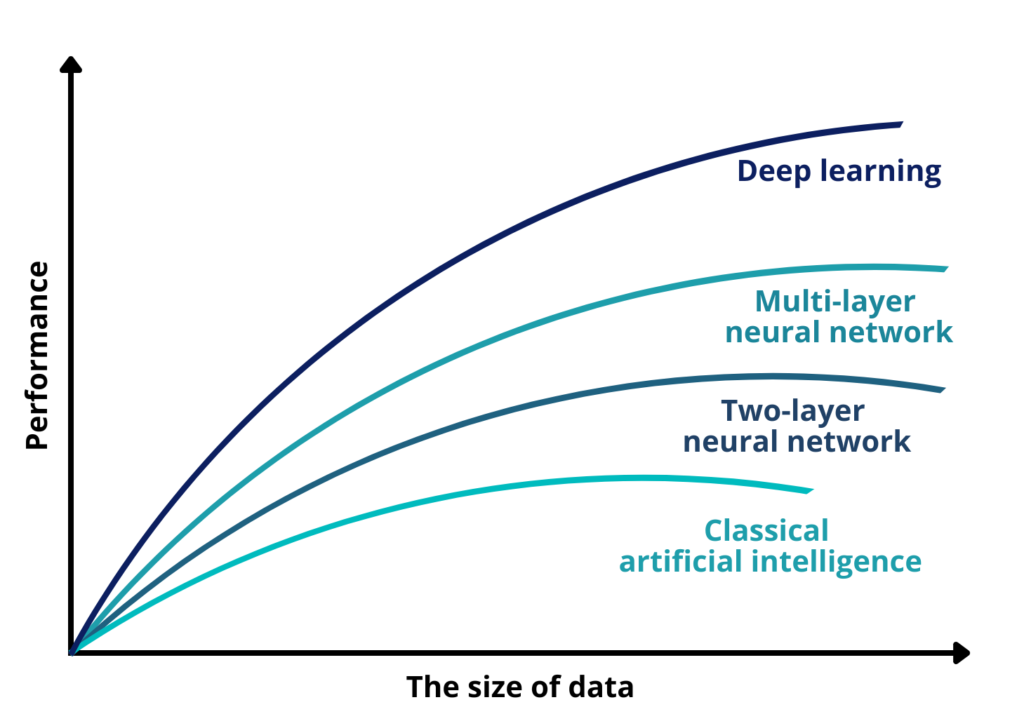
Neben der Datenqualität ist auch die Datenmenge ein entscheidender Faktor für den Erfolg eines KI-Projekts. Die Menge der Daten, die für das Training eines KI-Modells zur Verfügung stehen, kann einen erheblichen Einfluss auf die Genauigkeit, Verallgemeinerbarkeit und Leistung des Modells haben. Im Allgemeinen gilt: Je mehr Daten für das Training zur Verfügung stehen, desto besser wird das Modell abschneiden. Es gibt jedoch einen Punkt, an dem die Leistung des Modells durch zusätzliche Daten nicht mehr wesentlich verbessert werden kann.
Die für ein KI-Projekt erforderliche Datenmenge kann von mehreren Faktoren abhängen, darunter die Komplexität des zu lösenden Problems, die Anzahl der beteiligten Variablen und der gewünschte Genauigkeitsgrad. So benötigt ein Bilderkennungsmodell möglicherweise einen größeren Datensatz, um gute Ergebnisse zu erzielen, als ein Modell, das den Umsatz auf der Grundlage einiger weniger Variablen vorhersagt.
Mit einem großen Datensatz kann ein KI-Modell mehr über das Problem lernen, das es zu lösen versucht, was zu einer besseren Generalisierung und Leistung führt. Mit mehr Daten kann das Modell Muster und Beziehungen erkennen, die es mit einem kleineren Datensatz vielleicht nicht hätte erkennen können. Außerdem kann ein größerer Datensatz dazu beitragen, das Risiko einer Überanpassung zu verringern, die dann eintritt, wenn das Modell bei den Trainingsdaten gut abschneidet, bei neuen, noch nicht gesichteten Daten jedoch schlecht.
Die Beschaffung großer Datensätze kann jedoch eine schwierige Aufgabe sein, insbesondere für neue und Nischenanwendungen. In einigen Bereichen, wie z. B. im Gesundheits- oder Finanzwesen, sind die Daten aufgrund von Datenschutzbedenken oder Problemen mit dem Dateneigentum möglicherweise begrenzt. In solchen Fällen können Techniken zur Datenerweiterung, wie z. B. Datensynthese oder Transferlernen, eingesetzt werden, um den Umfang der verfügbaren Daten zu vergrößern.
Es sei darauf hingewiesen, dass ein großer Datensatz keine Garantie für gute Ergebnisse ist. Ein großer Datensatz mit Daten schlechter Qualität kann immer noch zu einem schlechten Modell führen. Daher sind sowohl die Menge als auch die Qualität der Daten wichtige Faktoren bei der Erstellung eines effektiven KI-Modells.
Bestimmung der optimalen Trainingsdatengröße für verschiedene AI-Modelle
Die Menge der für ein KI-Modell erforderlichen Trainingsdaten kann je nach Komplexität des Problems, der Qualität der Daten und der Art des verwendeten Modells variieren. Verschiedene KI-Modelle benötigen unterschiedliche Datenmengen, um effektiv zu trainieren. In diesem Kapitel wird erörtert, wie viele Trainingsdaten für einige gängige KI-Modelle erforderlich sind.
Lineare Regressionsmodelle
Lineare Regressionsmodelle werden verwendet, um eine kontinuierliche Variable auf der Grundlage einer Reihe von Eingabevariablen vorherzusagen. Diese Modelle erfordern in der Regel eine relativ kleine Menge an Trainingsdaten. Als Faustregel gilt, dass die Trainingsdaten mindestens das 10-20-fache der Anzahl der Eingabevariablen enthalten sollten. Wenn ein Modell zum Beispiel drei Eingabevariablen hat, wäre es ideal, mindestens 30-60 Trainingsdatenpunkte zu haben.
Modelle zur Bilderkennung
Bilderkennungsmodelle werden verwendet, um Objekte oder Muster in Bildern zu identifizieren. Diese Modelle erfordern große Mengen an Trainingsdaten, in der Regel Tausende bis Hunderttausende von Bildern. Die Menge der erforderlichen Daten kann von der Komplexität der Bilder und der Anzahl der verschiedenen Klassen abhängen, die das Modell zu erkennen versucht.
Modelle zur Verarbeitung natürlicher Sprache (NLP)
NLP-Modelle werden verwendet, um menschliche Sprache zu analysieren und zu erzeugen. Diese Modelle benötigen eine große Menge an Trainingsdaten, in der Regel Millionen von Wörtern oder Sätzen. Die Menge der erforderlichen Daten kann von der Komplexität der zu analysierenden Sprache, dem Bereich des Textes und der spezifischen Aufgabe, die das Modell ausführt, abhängen.
Empfehlungssysteme
Empfehlungssysteme werden eingesetzt, um Benutzern auf der Grundlage ihrer Vorlieben oder ihres bisherigen Verhaltens Artikel oder Produkte vorzuschlagen. Diese Modelle erfordern in der Regel eine mäßige Menge an Trainingsdaten, in der Regel Zehntausende bis Hunderttausende von Benutzer-Element-Interaktionen. Die Menge der erforderlichen Daten kann von der Komplexität des Modells und der Art der Empfehlung abhängen.
Es sei darauf hingewiesen, dass die Menge der für ein KI-Modell erforderlichen Trainingsdaten je nach Anwendungsfall, Datenqualität und Komplexität des Modells erheblich variieren kann. Es ist wichtig, die Leistung des Modells mit unterschiedlichen Datenmengen zu testen und zu bewerten, um die optimale Menge zu ermitteln.
Die Datenmenge der Trainingsdaten, die für verschiedene KI-Modelle erforderlich sind, kann sehr unterschiedlich sein. Es ist entscheidend, den spezifischen Anwendungsfall und die Komplexität des Modells zu bewerten, um die optimale Datenmenge zu ermitteln. Während einige Modelle, wie z. B. lineare Regressionsmodelle, nur eine geringe Datenmenge benötigen, sind für andere, wie z. B. Bilderkennungs- und NLP-Modelle, wesentlich größere Datenmengen erforderlich. Durch die Verwendung einer angemessenen Menge an hochwertigen Trainingsdaten können KI-Modelle effektiv trainiert werden, um zuverlässige und genaue Vorhersagen zu treffen.
Fazit
Der Erfolg eines KI-Projekts hängt in hohem Maße von der Qualität und Quantität der Daten ab, die zum Trainieren des Modells verwendet werden. In diesem Beitrag haben wir die Bedeutung von Datenqualität und -menge in KI-Projekten erörtert und wie sie sich auf die Leistung und Genauigkeit des Modells auswirken können.
Insgesamt sind Datenqualität und -menge zwei wesentliche Faktoren für den Erfolg eines KI-Projekts. Um die besten Ergebnisse zu erzielen, sind qualitativ hochwertige Daten und eine für das jeweilige Modell und den Anwendungsfall angemessene Datenmenge unerlässlich. Da KI weiterhin in verschiedenen Branchen und Anwendungen eingesetzt wird, ist es wichtig, der Qualität und Quantität der Daten, die zum Trainieren von KI-Modellen verwendet werden, Priorität einzuräumen, um optimale Leistung und Ergebnisse zu erzielen.
Zusammenfassend lässt sich sagen, dass KI-Projekte bei entsprechender Beachtung von Datenqualität und -quantität zuverlässige und genaue Vorhersagen liefern können, die es Unternehmen ermöglichen, fundiertere Entscheidungen zu treffen und Geschäftsergebnisse zu verbessern.
Sie möchten mehr über die individuelle Entwicklung von KI-Projekten erfahren und interessieren sich dafür wie auch Ihr Unternehmen von Künstlicher Intelligenz profitieren kann?
Kontaktieren Sie uns gerne für eine unverbindliche Beratung.