Blog

Machine-Learning-Modelle verstehen mithilfe
von Shapley-Werten
Von Marisa Müller am 24. Mai 2023
Viele Machine-Learning-Modelle sind als „Black Box“ bekannt, da es schwierig ist, zu verstehen, wie sie zu ihren Entscheidungen kommen. Es ist oft unklar, welche Features oder Variablen das Modell zur Vorhersage verwendet und wie sie gewichtet werden. Dies führt zu Bedenken hinsichtlich der Fairness, Robustheit und Vertrauenswürdigkeit von Machine-Learning-Systemen. Aus diesem Grund wird es gerade in kritischen Bereichen wie Gesundheitswesen, Finanzen und Justiz immer wichtiger, Methoden zu beherrschen, die ein solches Modell erklären. Erklärbare Künstliche Intelligenz (engl. explainable artificial intelligence, kurz XAI) bezieht sich genau auf diesen Ansatz: Machine-Learning-Modelle und andere KI-Systeme so zu gestalten, dass ihre Entscheidungen und Vorhersagen nachvollziehbar und verständlich sind.
Ein sehr spannender Ansatz hierzu ist die Verwendung von Shapley-Werten.
Shapley-Werte sind ein Konzept aus der kooperativen Spieltheorie, das in den letzten Jahren in der Welt des Maschinellen Lernens immer mehr an Bedeutung gewonnen hat. Sie wurden erstmals 1953 von Lloyd Shapley, einem Mathematiker und Ökonomen, eingeführt. Ursprünglich wurden sie dazu verwendet, den Beitrag jedes Spielers in einem kooperativen Spiel zu quantifizieren. Erst später wurde das Konzept der Shapley-Werte auf Machine Learning angewendet. Hier stellen Sie eine Methode dar, um die Beiträge einzelner Features zur Vorhersage eines Machine-Learning-Modells zu ermitteln und somit die Interpretierbarkeit von Modellen zu verbessern.
Die Idee hinter den Shapley-Werten ist relativ einfach. Man stellt sich vor, dass jedes Feature eines Machine-Learning-Modells ein Spieler in einem Spiel ist, das darauf abzielt, eine Vorhersage zu treffen. Die Vorhersage ist das Ergebnis des Spiels, und jedes Feature trägt auf unterschiedliche Weise zum Ergebnis bei. Um den Shapley-Wert eines Features zu berechnen, wird das Modell mit verschiedenen Subsets von Featuren trainiert und getestet. Der Beitrag jedes Features zum Ergebnis wird dabei gemessen und der durchschnittliche marginale Beitrag ergibt den Shapley-Wert.
In folgender Tabelle sind die Zusammenhänge nochmals komprimiert dargestellt:
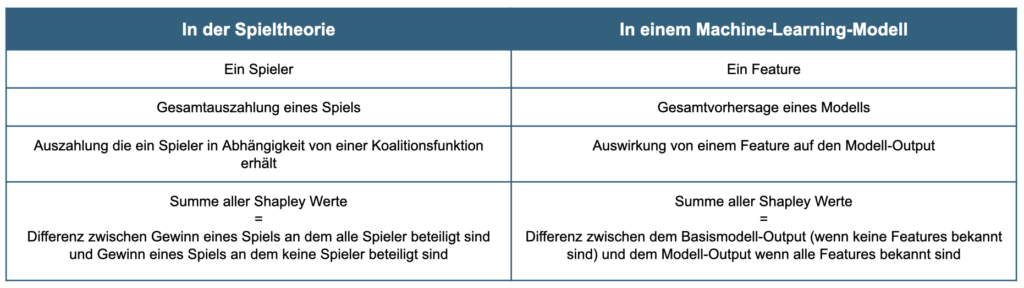


Ein Vorteil der Verwendung von Shapley-Werten besteht darin, dass sie es ermöglichen, den Beitrag von Features je Vorhersage zu messen. So kann beispielsweise der Beitrag von Features in verschiedenen Teilen des Datensatzes gemessen werden, was dazu beitragen kann, Bias in Modellen zu identifizieren und zu beseitigen.
In Python gibt es verschiedene Bibliotheken, die die Berechnung von Shapley-Werten für Machine-Learning-Modelle unterstützen. Eine der beliebtesten Bibliotheken ist die SHAP-Bibliothek, die speziell für die Berechnung von Shapley-Werten in Machine-Learning-Modellen entwickelt wurde. Diese Bibliothek bietet neben einer sehr leichten Berechnung der Shapley Werte auch verschiedene grafische Darstellungen an.
In folgender Grafik sehen Sie einen sogenannten Wasserfall-Plot. Dieser zeigt den Weg von der Basismodell-Vorhersage bis hin zur tatsächlichen Vorhersage des trainierten Modells.

Die Vorhersage des Basismodells ist am unteren Rand des Schaubildes zu sehen, in diesem Fall 2,124. Bei dem Basismodell handelt es sich meist um ein klassisches Mittelwertmodell. Der Plot stellt nun den Weg von der Mittelwert-Vorhersage bis hin zur tatsächlichen Modell-Vorhersage, welche am oberen Rand des Schaubildes abzulesen ist, dar. Dieser Verlauf gilt hierbei speziell nur für diese konkrete Vorhersage der links aufgelisteten Input-Parameter und die Werte sind demnach nicht vergleichbar mit einer allgemeinen Feature Importance. Direkt abzulesen ist hier beispielsweise, dass das Feature ‘HouseAge’ einen positiven Einfluss von +0.27 auf das Target hat, wobei ‘AveOccup’ keinen Einfluss auf diese konkrete Vorhersage hat.
Neben dem Wasserfall-Plot gibt es noch viele weitere interessante Tools, welche die SHAP Bibliothek zu bieten hat.
Insgesamt bieten Shapley-Werte eine nützliche Methode, um die Bedeutung von Features in Machine-Learning-Modellen zu verstehen und sie können hilfreich sein für alle, die derartige Modelle entwickeln oder analysieren. Sie können dabei helfen, Entscheidungen zu erklären und zu verbessern und sind somit ein wichtiger Bestandteil der Data-Science-Praxis.
Sie möchten mehr über die individuelle Entwicklung von KI-Projekten erfahren und interessieren sich dafür wie auch Ihr Unternehmen von Künstlicher Intelligenz profitieren kann?
Kontaktieren Sie uns gerne für eine unverbindliche Beratung.